
What is Computer Vision?
Artificial Intelligence has changed the world we live in. From the smartphones we use to rockets on space missions all are powered by AI. AI confers the ability of thinking like human beings to machines. With these capabilities, machines are now able to understand human languages and “see” like humans.
This is where the field of computer vision comes in. Computer Vision imparts machines to see and interpret their vision as humans do. There has been work going on in this domain since the 1950s when researches started working on re-creating the human eye.
The advancements in Artificial Intelligence, specifically deep learning has propelled computer vision to outperform humans on certain tasks like image classification.

Computer Vision is embedded in various applications which we use in our daily life. Some popular apps which use Computer Vision are Amazon Go, Google Lens, Tesla’s self-driving cars, and various face recognition software.
Computer vision driven face recognition applications are helping law enforcement across the world in identifying criminals in a crowd. Applications like Facetagr are even able to detect disguised faces thus taking this one step further in face recognition.
Computer vision has proved to be a boon in surveillance and military purposes as well. AI-powered drones are designed to give information about any suspicious terror activity by maintaining stealth.
Some AI-powered drones are used in disaster management systems as well, where the drone immediately detects victims who are stuck in a place during floods and other natural calamities and sends this information to the rescue team.
How does Computer Vision work?
To answer this question we have to first understand how a computer “sees” an image or video. For a computer, an image is nothing but a set of pixels that hold some numerical value in them that denotes the extent of its brightness. A pixel can be thought of as the smallest unit of an image which when combined constructs the original image.
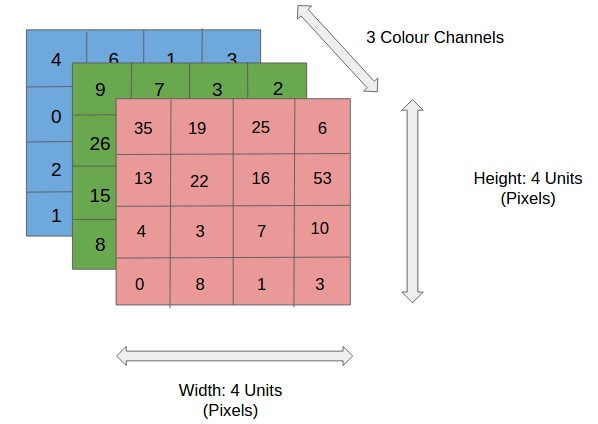
Each image can be broken down into a channel of 3 pixels, the red, green, and blue that when combined form the original image. Each of these channels contains information about the brightness of that unit. The bound is generally from 0 to 255, where 0 is the lightest and 255 the darkest. Grayscale images on the other hand are represented by a single channel, in which 0 represents white and 255 the darkest black.
How does the machine interpret an image?
Computer Vision algorithms have to interpret the image for performing the given task. The way in which images are interpreted varies from task to task. The most popular way of interpreting an image is through the use of Convolutional Neural Networks (CNN).
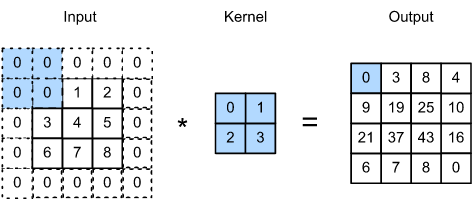
CNNs are a class of neural networks that are based on the convolutional operation. Mathematically, the convolution operation is one that acts on two functions and produces a third expressing how the shape of one is modified by the other. It is defined below in the context of CNNs.
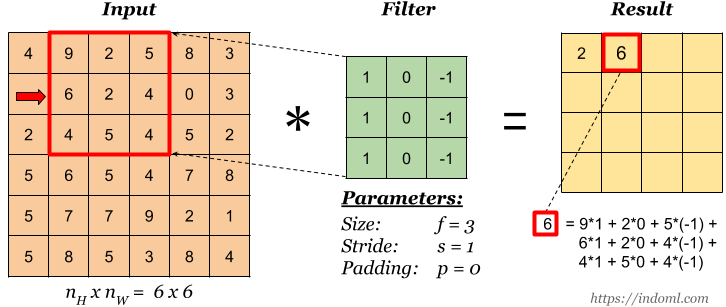
Here, each element of the filter (a 2X2 matrix in this case) is multiplied by the corresponding image value and the result is summed to give the output corresponding to it.
For understanding what CNNs are, we have to know what a neural network is. A Neural Network in deep learning is a set of neurons (basic computational units) that are arranged in a systematic manner in the form of layers. Neural Networks can be looked at as function approximators.
They learn a representation from the input and map it to the output with some confidence. CNNs are specially designed to cater to images. They operate on large chunks of images and each unit performs convolution operation on the images.
CNNs help to reduce the parameters of training (as compared to traditional neural networks) on image inputs. For example, if an image has 32X32 pixels then it will require 1024 neurons in the first layer to represent it. The subsequent layer will have 1024 X k weight parameters (in a fully connected network), where k is the number of neurons in the first hidden layer.
Hence, we see that the model parameters are increasing exponentially as new layers are being added. Whereas, with a CNN, just by using 3X3 filters we can reduce the number of parameters (9 here) significantly, and hence helping in faster training.
Also, the convolutional operation helps to find patterns in the image which are useful for the task at hand.
Working of CNNs
Convolution operation: As is the name of the network, the convolution operation is performed on the input image to transform the features into a hidden representation that is to be used in further computations.
Filter – Filter is a parameter set arranged in a specific manner (in a cube or cuboid shape) which acts on the input image and produces “activation maps”.
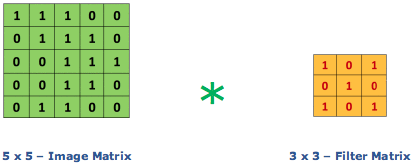
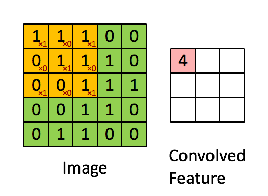
Special filters can help in blurring, sharpening, highlighting the borders of the input image. Hence, this operation helps us in extracting useful features from the image.

Strides: Strides refer to the number of pixels that the filter jumps while sliding over the input image. By default the stride is set to 1, however, it can be changed to higher values.
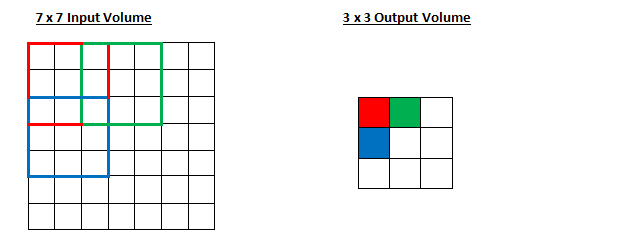
By using higher strides, we can reduce the dimension of the output activation maps.
Padding: Padding refers to adding zeros around the input image to get the desired dimension of the activation map after the convolutional operation.
Non-linearity – Non-linearity is an integral part of deep learning neurons. Introducing non-linearity allows for better learning the mapping function. In the case of CNNs ‘ReLu’ is used as the activation function i.e. relu activation function is applied to the result of each convolutional operation.
Pooling Layer: Pooling layers help to decrease the dimensionality of the image (when it is too large) with the retention of important information.
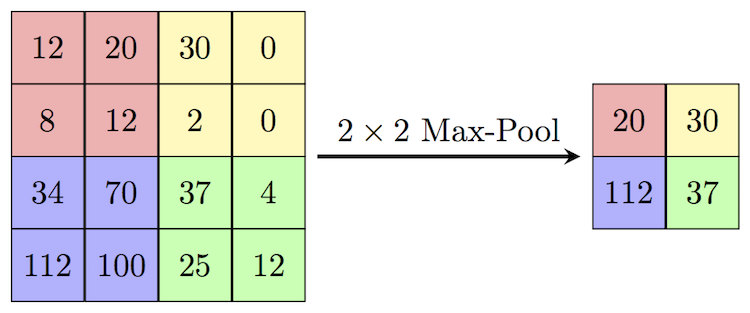
After performing these operations on an image and extracting the useful information, it is fed to a feed-forward neural network for the downstream task.
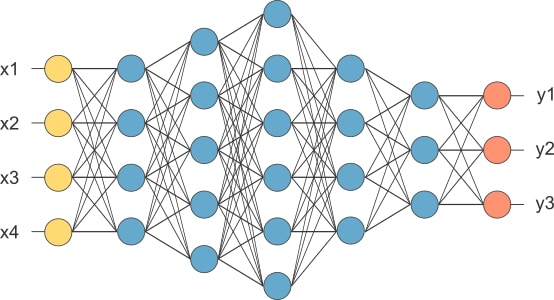
The task can be image classification, object detection, etc.
The entire CNN architecture is shown below
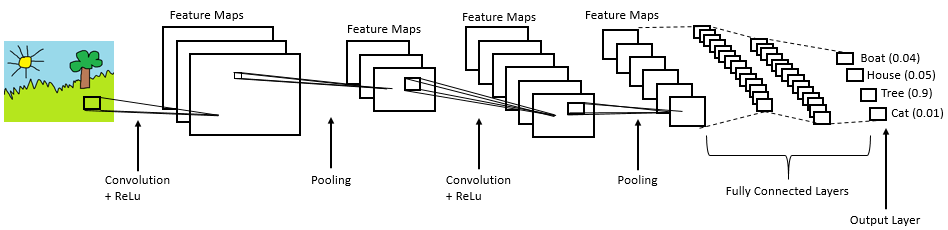
On a large scale CNNs have the capability of doing the following:
- Image Segmentation – Differentiating the foreground and the background of the image. This is used to find edges in various images.

- Finding textures: The CNNs in each layer learn to identify a pattern (or texture) underlying in the image. This helps in performing tasks like image classification and object recognition.

An Open Source Library for Computer Vision:
OpenCV
OpenCV is one of the most popular open-source libraries for computer vision and machine learning. The OpenCV library provides access to more than 2500 traditional and state-of-art computer vision algorithms for performing tasks such as
- Recognizing faces,
- Identifying objects,
- Classifying human actions in videos,
- Tracking camera movements, tracking moving objects,
- Extracting 3D models of objects,
- Producing 3D point clouds from stereo cameras,
- Stitching images together to produce a high-resolution image of an entire scene,
- Finding similar images from an image database,
- Removing red eyes from images taken using flash,
- Following eye movements,
- Recognizing scenery and establishing markers to overlay it with augmented reality, etc.
OpenCV has over 18 million downloads making it the most popular Computer Vision library. It is easy to use and has the ability to perform complex computer vision oriented tasks.
The most appealing part of OpenCV is that it has features to support all primitive operations on images and videos in the easiest way. One can define data types to hold different kinds of images and perform operations on them. It handles tasks like storing an image formed from other images, performing operations on videos in a smooth manner.
Some interesting features of OpenCV are:
- Image Processing operations: Operations such as image filtering, morphological operations, geometric transformations, color conversions, drawing on images, histograms, shape analysis, motion analysis, feature detection can be easily performed using OpenCV.

- 3D Reconstruction: 3D reconstruction is an important topic in Computer Vision. Given a set of 2D images, we can reconstruct the 3D scene using the relevant algorithms. OpenCV provides algorithms that can find the relationship between various objects in these 2D images to compute their 3D positions. We have a module called calib3d that can handle all this.
- Feature Extraction: As discussed earlier, the human visual system tends to extract the salient features from a given scene so that it can be retrieved later. To mimic this, people started designing various feature extractors that can extract these salient points from a given image. Some of the popular algorithms include SIFT (Scale Invariant Feature Transform), SURF (Speeded Up Robust Features), FAST (Features from Accelerated Segment Test), and so on. Modules like features2d, xfeatures2d help in performing the same.
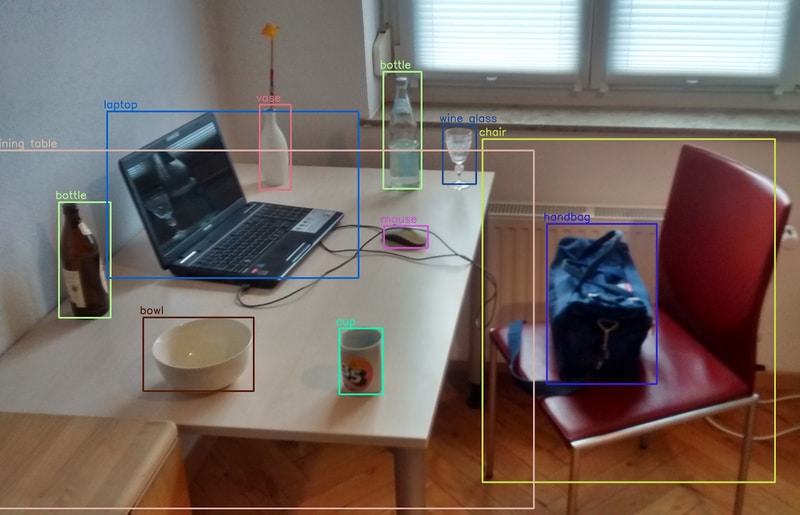
- Object Detection: This refers to detecting objects in an image and rightly identifying them with their class. Typical object detection algorithms work by using bounding boxes around the image to determine its position and label it. OpenCV has modules called objdetect and xobjdetect that provide the framework to design an object detector. One can use it to develop detectors for random items such as sunglasses, boots, and so on.
- Machine Learning: OpenCV has a library called ml in which there are readily usable ML algorithms like Bayes Classifier, K-Nearest Neighbors, Support Vector Machines, Decision Trees, Neural Networks, and so on. Machine learning algorithms are used extensively to build systems for object recognition, image classification, face detection, visual searches, and so on.
Popular Examples of Computer Vision:
- Autonomous Vehicles: Self-driving cars by Uber, Tesla are an example of these. They make use of live visual input to perform object detection, lane markings to drive safely.
- Google Translate app: When pointed to a foreign language the app displays the translation in the preferred language in real-time. This makes use of optical character recognition techniques in Computer Vision.
- Facial Recognition: This is used by government officials for spotting criminals in a crowd and to maintain law and order. Apps like facetagr are very efficient in performing facial recognition.
- HealthCare: More than 90% of the body scans are image-based. Using deep learning these images can be used for the prediction of cancer and other harmful diseases at the right time.
- Predictive Maintenance: Computer Vision is used for monitoring the health of machines and infrastructures. Predictive Maintenance using computer vision techniques is very useful as it helps the company save time and money. Shell, an oil and gas company, employs this technique for maintaining its machinery.
- Automatic Inventory Management: This refers to keeping a track of the inventory in a shop or a supermarket. Computer Vision based robots are designed to perform this task automatically by making use of object detection algorithms. For example, Walmart is expanding the use of Bossa Nova Robotics shelf-scanning robots to 350 of their stores.
- Optimizing marketing solutions: Computer Vision helps in optimizing marketing solutions and providing new content for marketing. One of the biggest challenges for any online marketing company is generating new content. Generative Adversarial Networks are neural networks that are making this process a lot easier. GANs utilize AI tools such as CV applications to help the user to create realistic visual content. Japanese technology company ModelingCafe has used this application to create lifelike images of created fashion models.
Recent Advances in Computer Vision:
Object Detection:
Object Detection is a classical computer vision task in which objects are detected from an image. Recent advancements include the invention of higher accuracy and faster deep learning based architectures that perform object detection. For example, YoloV3 is a new CNN based architecture that can detect small objects in the image accurately as well.
Image Segmentation:
This task involves grouping of similar pixels to form a meaningful entity. Mask R-CNN is a new architecture that helps in improving the accuracy of segmentation. Mask R-CNN architecture has outperformed all other existing models for segmentation.
Generative Adversarial Networks:
Yann LeCun, a prominent deep learning researcher, described it as “the most interesting idea in the last 10 years in Machine Learning”. Generative Adversarial Networks belong to the set of generative models. It means that they are able to produce/ generate new content. The ability to generate new content has proved to be a boon in various domains of computer vision and has changed the way we look at it. For example, This person doesn’t exist is an online free website that generates the faces of people who look absolutely real but don’t actually exist. It makes use of GANs to generate these fake images.
Conclusion
Computer Vision is indeed one of the most booming topics. By imparting machines the ability to see we empower them with solving various important tasks. There have been many advancements in computer vision in the last decade. In the current pace of its development, there is a huge scope for many more impactful advancements and applications.
If you are looking to develop applications using Natural Language Processing you can contact us at enquiry@queppelintech.com




